Long time ago when I gave a quick introduction to Fourier transform, I highlighted the fact that a lot of observations are sparse in nature.
We are not dealing with Fourier transform today, and yet we are still looking at something sparse.
Setting: Original Video
Now spend around 10 seconds and look at the following video.
We can always see that there are some people present in the video. And for some reasons you just do not want to see any people in the video.
So our goal is: to create a new video out of the original one, containing the background only.
The non-mathematical approach:
Few weeks ago I came across a very interesting video by a French photographer, who managed to produce an empty London (and also Time Square in the US):
His approach is explained in his tutorial video at: http://vimeo.com/90837405. What he used were basically:
- Video processing software,
- Photoshop, and
- Two Bunnies.
Since video is basically a sequence of frames, what he did (and we will also do) is to first extract the frames from the original video. It is then clear that the photoshop was used to remove any unwanted items in the street.
And in case you wonder why the two bunnies are necessary, here is the explanation of the French guy.

Working with Time Square

Psychological Support
What Mathematicians Do
I really appreciate the effort of the French photographer, and actually enjoyed his video very much. But it is a bit too time-consuming.
The mathematical trick we will use is based on a simple observation: that the background is not changing – otherwise we won’t call it a background. And intuitively, we can write something like
Frame(k) = Background + People(k).
Where Frame(k) refers to the k-th frame (our example: 24fps, and we have around 170 frames in total), and People(k) refers to the position of any people on top of the (constant) background.
Some Linear Algebra
If you have learnt some linear algebra in high school or college, you probably know diagonalization (or spectral decomposition).
The basic idea is to write a square matrix 

where P is some invertible matrix, the columns of which are called eigenvectors, and D is a diagonal matrix, whose diagonal entries are known as eigenvalues.
What your teacher may not have taught you is the following fact: the absolute size of the eigenvalue is related to the importance of the eigenvector: the larger the absolute value of eigenvalue, the more important the respective eigenvector is.
Take a very simple example.

Now we can see that 2 of the eigenvalues are very small (0.001 and 0.002) compared to the largest one (1). If we simply replace these small eigenvalues by 0, call the new matrix E, and compute 

A similar decomposition is called singular value decomposition, which allows us to write A as 
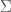
SVD can somehow be conceived as a general version of diagonalization, since it works for any matrices, not only square ones, and one of the matrices is “diagonal” the entries of which are related to eigenvalues. Instead of talking about eigenvalues, we talk about these “singular values”, and similar conclusion holds: the larger singular value suggests that the corresponding vector is more important in describing the original matrix.
If you do not know SVD and want more details, you are encouraged to look at wikipedia.
What is sparse?
Clearly, the background is not sparse in a particular frame: it occupies most of the area of a particular screenshot. We know it is “sparse” in the video, but how can we translate the sparsity into mathematics?
- First step: recall that a video is basically a sequence of frames.
- Second step: a frame is basically three matrices.
The second step will be clear if you know a bit about computer graphics. Firstly, a frame is an image, and an image is a rectangular array of pixels. Each pixel can be represented by a number, but by convention we use the RGB representation for the colour of a particular pixel, so we get three numbers, corresponding to the red, green and blue colour. Therefore we have the “red”, “green” and “blue” matrices.
- Third step: for each frame, rewrite it as a column vector (“vectorizing”)
“Vectorization” is just a fancy name. What it means can be explained by the following example.

In case of RGB representation, you may first write down the “red column”, and put the “blue” and then “green column” beneath it, forming one column vector as a whole. Clearly this is not the only way you convert a matrix (or 3 matrices) to a vector. As long as you are consistent you will be fine.
- Fourth step: after vectorizing the frames, put them together and form a matrix, i.e. first frame -> first column, etc. Call it
.
- Fifth step: after we get the matrix, we perform singular value decomposition
.
And as we described above,
- Sixth step: create new matrix
from
- Seventh step: construct the new matrix
, then reverse the operations to get back the sequence of frames.
Of course, finally, convert the sequence of frames back to a video.
What is the result?
Well, this is the video I obtained.
In case you want to try, this is the MATLAB code I used:
%Read the video file
video_o = VideoReader(‘original.mp4′);
%Extract frames from the video
img_d = double(read(video_o));%get the size of the “frames” – ims
%ims(1): width; ims(2): height
%ims(3) = 3 => RGB representation
%ims(4) = total amount of frames extracted from the video
ims = size(img_d);
img_work = zeros(ims(1)*ims(2)*ims(3), ims(4));%converting to 2D matrix by vectorization
for i_ = 1:ims(4)
tmp = img_d(:,:,:,i_);
%turn each matrix (frame) to a column vector
img_work(:, i_) = tmp(:);
end
%Singular Value Decomposition
[A, B, C] = svd(img_work,0);
%Keep the largest singular value B(1), and set all other entries to 0
B(2:end) = 0;
%Get the background;
img_n = reshape(min(max(A*B*C’,0),255), ims(1), ims(2), 3, ims(4));%Converting the frames back to video
video_n = VideoWriter(‘new.mp4’, ‘MPEG-4’);
video_n.FrameRate = 24;
open(video_n);
writeVideo(video_n, uint8(img_n));
close(video_n);
(And if you are in doubt, I am NOT cheating: if you are careful enough you should see some changes in the brightness from frame to frame in the new video.)
